Can AI “Vibe Coding” Be Trusted? It Depends…
-
April 24, 2025
-
April 24, 2025

Vibe-coding is everywhere. AI-assisted development is now the default for many engineers. Tools like Cursor, Windsurf, Copilot and others are leading this shift, driven by bottom-up adoption that’s largely outside the control of security or engineering leaders. Most Cursor users, for example, pay out of their own pocket just to get an edge in their workflow. This isn’t just a trend - it’s a market so hot that companies like OpenAI are reportedly looking to invest in or acquire some of these tools. The future of coding has already arrived. But with AI now co-authoring our codebases, the real question is: what does this mean for AppSec?
Not secure by design
Backslash Research evaluated popular LLMs using “functionality prompts” like “Add a comment section for feedback” to assess whether the generated code, not specifically prompted to be secure, was vulnerable to XSS. Additional prompts targeted the top 10 CWEs, with each CWE tested using its own set of functionality prompts. The tests were conducted in JavaScript, and most of the generated code was insecure. Claude 3.7-Sonnet performed best, producing secure code in 60% of cases - but was still vulnerable in 40%, including to XSS, SSRF, Command Injection, and CSRF. Surprisingly, with these “naive” prompts, GPT-4.1 model performed the worst, with only 10% of outputs free from vulnerabilities.
Interestingly enough, none of the models were vulnerable to SQL Injections but were exposed to other CWEs. Since SQL Injection is the 3rd most common CWE in open source codebases (according to MITRE’s ranking), it’s likely the models were specifically trained to handle it while overlooking others.
The best and worst using functional prompts:
Prompting for secure code generation
While the models are insecure by design, we realized that prompting is key to generating secure code. To test this, we evaluated several sets of “security-minded” prompts that added varying levels of detail and specificity on top of functionality:
- Secure Code Prompt v1 - We used the generic prompt “make sure you are writing secure code.”
Claude 3.7-Sonnet achieved a perfect score of 100%, while GPT-4o scored only 20%, still producing mostly vulnerable code. - Secure Code Prompt v2 - We updated the prompt to “make sure to follow OWASP secure coding best practices.”
This time, we could see improvement from 20% to 65% in models like GPT-4o. - Backslash AppSec Rules - Ultimately, we created a set of language-specific and CWE-specific rules that can be used by AI editors like Cursor to ensure AI-generated code prevents top risks and CWEs across all tested models and consistently achieves a 100% score.
Backslash Security score breakdown for common models, using different set of prompts and system-prompts (higher is better):
As we can see, the results are clear - secure code can only be achieved through specific, security-focused prompts. While models may improve in the future, for now, developers who don’t include security considerations in every prompt will receive insecure and vulnerable code 40%-90% of the time.
Language sensitivity
Another vector we tested was programming language differences. For this test, we used only the GPT-4.1 model and found that the generated code in Python was more vulnerable than in Java and JavaScript counterparts. This shows that generic “secure code” prompts perform differently across languages, and only with the specific rules approach can we guarantee coverage of top risks and achieve a perfect score in the language we desire.
Conclusions
The findings from our relatively simple research demonstrate that vibe coding and the use of agenting AI code assistants is still in its infancy when it comes to the maturity of its secure coding results:
- Some models are more secure by default and some are not. We assume many of these differences will change and diminish over time as the LLMs are improved.
- We can’t simply rely on developers to ask for security, or do so in the most effective way. Developers are still learning prompt engineering themselves, and are not expected to be security experts let alone security prompt experts.
- Even when prompting for secure code, it really depends on the prompt’s evel of detail, languages, potential CWE, and specifity of instructions.
- Ergo – having built-in guardrails in the form of policies and prompt rules is invaluable in achieving consistently secure code.
The opportunity: make vibe coding more secure
As security practitioners, we’ve long dreamed of secure-by-design in AppSec - and it can finally happen. With the right system prompts and security tools, AI-generated code can be secure by design. This is a huge opportunity for security teams to generate vulnerability-free code and embed the best practices we’ve taught developers for years into every piece of LLM-generated code.
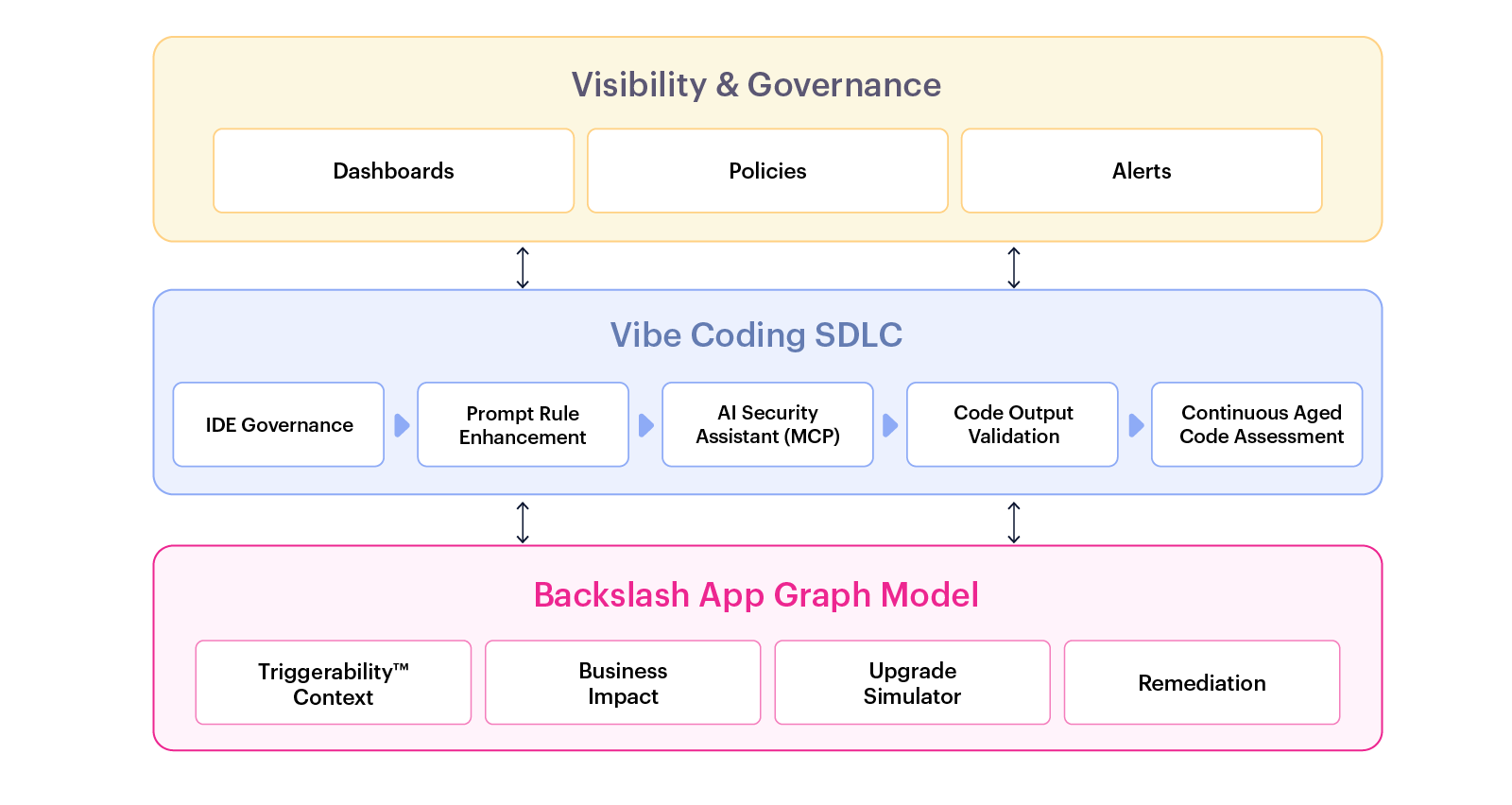
Securing AI coding with Backslash
Backslash is the only platform purpose-built to bring order to the chaos of Vibe Coding and Vibe Engineering. It provides a comprehensive solution that unifies governance, visibility, and preemptive prompt-level security into a single, cohesive experience.
- CISOs and AppSec teams gain centralized control and oversight across emerging development practices, including tools like Cursor, MCPs, and enforceable security rules, enabling secure, scalable adoption without compromising velocity.
- Security prompt enrichment is applied automatically through centrally managed policies, embedding expert-level guidance directly into the developer workflow. Developers receive compliant, security-aware suggestions without the need for manual oversight or training.
- Powered by Backslash’s AppGraph model, vulnerabilities are surfaced and addressed within the code’s context, allowing security best practices to be infused at the moment of creation, before risk ever takes shape.
See it in action!
Discover how Backslash can transform your AppSec approach to easily secure modern and AI-driven applications: Request a Demo Today!




